Building a Scalable data Processing Pipeline with Kafka and Docker Compose
Building a scalable data processing pipeline is crucial for applications that require efficient handling of large volumes of data in real-time.
Reading_time: 10 min
Tags: [ApacheKafka, DockerCompose, Dataprocessing, ImageProcessing, DataPipeline, RealTimeProcessing, Python]
Comprehensive Guide — A Step-by-Step Guide to Efficient Asynchronous Kafka Image Processing
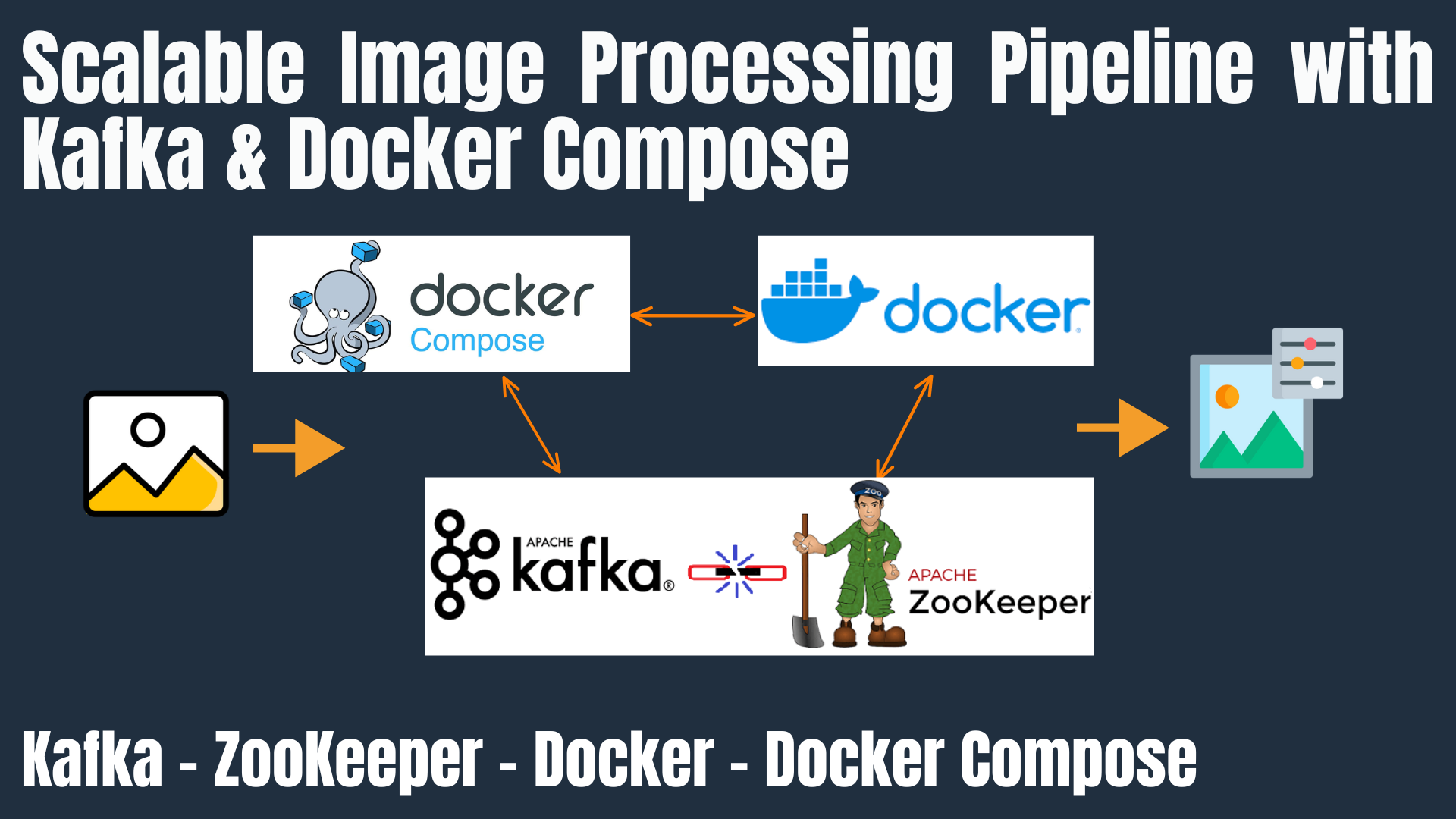
Building a scalable data processing pipeline is crucial for applications that require efficient handling of large volumes of images in real-time. In this tutorial, we’ll guide you through the process of setting up an image processing pipeline using Apache Kafka for message brokering and Docker Compose for container orchestration. By the end of this guide, you’ll have a robust system capable of processing images asynchronously, ensuring scalability and resilience.
Table of Contents:
Introduction
System Architecture Overview
Setting Up the Development Environment
Building and Containerizing the Application
Configuring Apache Kafka
Deploying with Docker Compose
Running and Monitoring the Pipeline
Conclusion and Next Steps
Complete code available in here
1. Introduction
In modern applications, processing images efficiently is essential, especially when dealing with large datasets or real-time requirements. A scalable image processing pipeline allows for the ingestion, processing, and storage of images in a manner that can handle increasing loads gracefully. By leveraging Apache Kafka, Zookeeper and Docker Compose, we can create a system that is both scalable and easy to manage.

2. System Architecture Overview
Our pipeline consists of the following components:
Image Source: The origin of images, which could be an application uploading images, a database, or an external service.
Kafka Producer: Receives images from the source and publishes them to a Kafka topic.
Kafka Broker: Acts as an intermediary, storing and forwarding messages from producers to consumers.
Image Processing Service: Consumes images from the Kafka topic, processes them (e.g., background removal, background replacement, upscaling), and stores the results.
Storage: A location to save the processed images, which could be a file system, database or cloud storage.
Monitoring and Logging: Tools to track the performance and health of the pipeline.
3. Setting Up the Development Environment
Before we begin, ensure you have the following installed:
Docker: For containerizing and running our services.
Docker Compose: To orchestrate multi-container Docker applications.
Python 3.x: For writing the image processing service.
Kafka-Python Library: To interact with Kafka from our Python application.
4. Building and Containerizing the Application
We’ll create a Python application that processes images by performing tasks such as background removal, background replacement, and upscaling. Each of these tasks can be handled by separate services or combined into a single service, depending on your requirements.
a. Application Structure:
api/app.py: The entry point of the application.
services/bg_removal_service.py: Handles background removal.
services/bg_replace_service.py: Handles background replacement.
services/upscale_service.py: Handles image upscaling.
utils/constants.py: Contains constant values used across the application.
b. Dockerfile:
We’ll create a Dockerfile to containerize our application:
# Use the official Python image from the Docker Hub
FROM python:3.8-slim
# Set the working directory in the container
WORKDIR /app
# Copy the requirements file into the container
COPY requirements.txt .
# Install the required Python packages
RUN pip install --no-cache-dir -r requirements.txt
# Copy the rest of the application code into the container
COPY . .
# Run the application
CMD ["python", "main.py"]
5. Configuring Apache Kafka
Apache Kafka is a distributed streaming platform that allows for building real-time data pipelines. We’ll set up Kafka using Docker Compose.
a. Docker Compose Configuration:
Create a docker-compose.yml file to define our services:
version: '3.7'
services:
zookeeper:
image: confluentinc/cp-zookeeper:latest
platform: linux/arm64
container_name: zookeeper
environment:
- ZOOKEEPER_CLIENT_PORT=2181
ports:
- "2181:2181"
networks:
- kafka_network
kafka:
image: confluentinc/cp-kafka:latest
platform: linux/arm64
container_name: kafka
environment:
- KAFKA_ADVERTISED_LISTENERS=INSIDE_KAFKA://kafka:9092,OUTSIDE_KAFKA://kafka:9093
- KAFKA_ADVERTISED_LISTENERS=INSIDE_KAFKA://kafka:9092,OUTSIDE_KAFKA://localhost:9093
- KAFKA_LISTENERS=INSIDE_KAFKA://0.0.0.0:9092,OUTSIDE_KAFKA://0.0.0.0:9093
- KAFKA_LISTENER_SECURITY_PROTOCOL_MAP=INSIDE_KAFKA:PLAINTEXT,OUTSIDE_KAFKA:PLAINTEXT
- KAFKA_LISTENER_SECURITY_PROTOCOL=PLAINTEXT
- KAFKA_LISTENER_NAME_INSIDE_KAFKA_SECURITY_PROTOCOL=PLAINTEXT
- KAFKA_LISTENER_NAME_OUTSIDE_KAFKA_SECURITY_PROTOCOL=PLAINTEXT
- KAFKA_INTER_BROKER_LISTENER_NAME=INSIDE_KAFKA
- KAFKA_OFFSETS_TOPIC_REPLICATION_FACTOR=1
- KAFKA_ZOOKEEPER_CONNECT=zookeeper:2181
volumes:
- ./data/kafka:/var/lib/kafka/data
depends_on:
- zookeeper
networks:
- kafka_network
healthcheck:
test: ["CMD", "kafka-broker-api-versions", "--bootstrap-server", "kafka:9093"]
interval: 60s
retries: 5
image_processing_service:
build:
context: ..
dockerfile: docker/Dockerfile
ports:
- "5000:5000"
depends_on:
kafka:
condition: service_healthy
environment:
- KAFKA_BROKER=kafka:9093 # Internal broker address
networks:
- kafka_network
networks:
kafka_network:
driver: bridge
6. Deploying with Docker Compose
With our docker-compose.yml file in place, we can start our services:
docker-compose up -d
This command will build and start the Zookeeper, Kafka, and application services in detached mode.
7. Running and Monitoring the Pipeline
Once the services are running, the application will begin consuming images from the Kafka topic, processing them, and storing the results.
Check Topics
List all topics in Kafka to ensure tasks are being published correctly:
docker exec -it kafka kafka-topics - bootstrap-server kafka:9092 - list
8. Monitoring:
To monitor the pipeline, you can use Kafka’s command-line tools or set up a monitoring stack with Prometheus and Grafana. For a comprehensive guide on setting up such a monitoring stack. Monitor Apache Kafka Clusters with Prometheus, Grafana, and Confluent
9. Scalability: Designing for High Throughput
To ensure that your image processing pipeline can handle increased workloads and maintain performance,consider the following strategies:
Refer here for more scalability options:
A. Horizontal Scaling
Kafka Cluster
Cluster Deployment: Set up a Kafka cluster with multiple brokers to manage higher message throughput.
Replication and Partitioning: Implement a replication factor for fault tolerance and partition topics to distribute the load across brokers.
Application Instances
Orchestration: Utilize orchestrators like Kubernetes or Docker Swarm to deploy multiple instances of your application.
Consumer Groups: Configure these instances to subscribe to Kafka topics using consumer groups, enabling efficient distribution of message processing.
B. Cloud Deployment
Managed Kafka Services
- Service Selection: Opt for cloud-managed Kafka services such as AWS Managed Streaming for Apache Kafka (MSK), Azure Event Hubs, or Confluent Cloud to minimize operational overhead and enhance reliability.
Serverless Compute
Processing Service Migration: Transition your processing services to serverless platforms like AWS Lambda or Google Cloud Functions to benefit from auto-scaling based on message volume.
Load Balancing
- Load Balancer Deployment: Implement a load balancer (e.g., AWS Elastic Load Balancing, Google Cloud Load Balancing) in front of your application API to manage and route incoming requests efficiently.
C. Optimized Message Processing
Batch Processing
- Consumer Optimization: Implement batch processing for Kafka consumers to reduce the overhead of frequent I/O operations and improve throughput.
Message Filtering
- Broker-Level Processing: Utilize Kafka Streams or ksqlDB to filter or preprocess messages at the broker level before they reach consumers.
Priority Queues
- Topic Prioritization: Establish multiple Kafka topics with varying priorities for time-sensitive or critical tasks to ensure efficient processing.
D. Monitoring and Auto-Scaling
Monitoring Tools
- Integration: Incorporate monitoring tools like Prometheus, Grafana, or cloud-native solutions (e.g., AWS CloudWatch) to track system health and monitor Kafka message lag and broker performance.
Auto-Scaling Policies
- Configuration: Set up auto-scaling policies for both Kafka brokers and application instances based on metrics such as CPU usage, memory utilization, and Kafka consumer lag.
E. Data Persistence
Data Lakes
- Archiving: Use cloud-based storage solutions (e.g., Amazon S3, Google Cloud Storage) to archive processed images or messages for long-term retention and analytics.
Database Scaling
- Metadata Storage: For metadata storage, migrate to a distributed database like Amazon Aurora, MongoDB, or Google Cloud Spanner to enable horizontal scalability.
F. Workflow Orchestration
Orchestrator Integration
- Tool Selection: Integrate workflow orchestrators like Apache Airflow, Prefect, or Argo Workflows to manage complex pipelines, handle task dependencies, retries, and scheduling for streamlined processing.

By implementing these strategies, you can design an image processing pipeline that is both scalable and efficient, capable of handling high throughput in various deployment environments.
Conclusion
In this tutorial, we’ve walked through the process of building a scalable image processing pipeline using Apache Kafka for message brokering and Docker Compose for container orchestration. By leveraging these technologies, we’ve created a system capable of handling high-throughput image processing tasks efficiently.
Implementing monitoring and logging with tools like Prometheus and Grafana further enhances the pipeline’s robustness, allowing for proactive issue detection and performance optimization. This setup ensures that the system remains resilient and can scale to meet increasing demands.
As you continue to develop and optimize your image processing pipeline, consider exploring additional enhancements such as:
Scaling Services: Implementing auto-scaling mechanisms to handle varying workloads.
Advanced Monitoring: Setting up alerts and more detailed dashboards to monitor specific metrics.
Security Measures: Ensuring secure communication between services and implementing authentication where necessary.
By continuously refining your pipeline and incorporating best practices, you’ll be well-equipped to handle complex image processing tasks in a scalable and efficient manner.
Thanks for Reading!
Connect with me on Linkedin
Find me on Github
Visit my technical channel on Youtube